Tracing SRE’s journey in Zalando - Part II
Follow Zalando's journey to adopt SRE in its tech organization.

Principal Software Engineer
Welcome to the second part of our journey establishing SRE in Zalando. You’ll find the first part here. Don’t miss out on the third and final post in one week.
2018 - The Return of SRE
In our previous blog post we left it with the plans for Site Reliability Engineering (SRE) in Zalando having to change. So, what were those changes and what were the challenges we faced in this new iteration? In this blog post we’ll go straight to the first quarter of 2018, when two sister SRE teams were bootstrapped around the same time in different departments. One of them was the SRE Enablement team in Digital Foundation (DF - a central functions department). The other was the Digital Experience SRE team (DX - the department responsible for the customer facing part of our Fashion Store). The last one was created from a grassroots initiative, but the DF one was reimagined by management of that department.
Since the decision made back in 2017 to grow the number of teams on call, the issue with overwhelmed on call teams was gone. As expected, the side effect of that decision was that teams were now much more aware of the operational burden of their services and would take steps to reduce that burden. Post-Mortems started becoming a regular practice in 2017, which also helped (although the practice was not yet well established). But while teams were slowly becoming more ‘operationally capable’, the complexity of our platform was growing at a much faster pace, with no one to keep a holistic view on the service landscape. You’ll notice from the name of the DF team that there is already something implied: SRE Enablement. This is where the new team differentiates itself from the 2016 initiative. The challenge that gave purpose to the Enablement team was raising the bar on our operational practices. This was around: monitoring, incident response, chaos engineering, resilience engineering.
Both SRE teams had very limited resources (only 2 engineers each), and they obviously shared the same goals. To better align the efforts of both teams, an SRE Program is kicked-off that unites them around common goals. As before, the practices and mindset described in Google’s original SRE book are used as the main inspiration for our own SRE teams. The teams were composed of experienced engineers, with a strong background in software development, knowledge of systems engineering, and incident response (very much aligned with the profile that was outlined back in 2016). These engineers also enjoyed a fair amount of social capital across the organization, which greatly facilitated the collaboration with other teams.
Compared to the previous iteration, the SRE Program was not aiming at significant organizational changes. This gave some degree of freedom regarding the projects the Program would tackle. At the beginning of the Program, the 2 teams got together and made a list of all the topics that were SRE relevant and that we wanted to work on. When we were done, the size of the list was considerable (there are so many interesting, relevant and challenging topics in SRE). With our limited capacity, however (6 team members between the two teams - 1 Lead, 1 Program Manager, 4 Engineers), we had to be careful when picking our initiatives. Although this meant that we had to drop many of the topics we wanted to work on, that careful selection contributed significantly to the success of the Program, and the reputation we built for the SRE name within the company.
The SRE Program took on the rollout of Distributed Tracing across the engineering organization, helped improve the Page Load Time for some of Zalando’s pages, staffs the newly created Incident Commander role, and helps with Cyber Week preparations, namely Load Tests. SREs, in the role of Incident Commanders, provided on-site support during Black Friday in a dedicated Situation Room. SREs also worked with other teams on efficiency topics that led to significant cost savings with cloud infrastructure while preserving reliability targets.

SLOs, as were introduced back in 2016 were still in place, with hundreds of new services specifying SLOs. Despite the growing number of SLOs, they were still not used to help the teams strike a balance between feature development and operational improvements. One of the things that made it more challenging was the fact that Zalando runs many thousands of services in production. We figured that not all of them had the same relevance. To try to put some structure into the SLOs we had, Service Tier definitions were published. To help with the Service Tiers, a new SLO reporting tool was developed. The new tool defined canonical SLIs and used the tier classification. However, this work was limited in scope. They targeted a single department, Digital Experience, home to one of the SRE teams. Services in other departments were not included in this effort and there was no mandate for them to adopt the new Service Tier definitions. Attempting to roll this out for the entire company (>4000 services) would not be feasible.
On the cultural level, the SRE Program took ownership of the SRE Guild. Guilds in Zalando are self-organized groups of colleagues, sharing a common interest, that meet regularly to exchange knowledge. The SRE Guild was actually a remnant from the 2016 initiative, but was left dormant. We saw the SRE Guild as an agent of cultural change to help us spread the SRE mindset. We then devoted efforts to develop a format that would be engaging and sustainable. Guild sessions provided a regular event with talks around all things SRE, whether it’s presenting the work of the SRE Program, or giving the floor for other teams or engineers to share knowledge. Postmortems became a regular topic in these sessions. This format is still in place today.

Despite the success of the SRE Program, the fact that the individual teams were part of different organizations with different reporting chains led to some challenges related to the priorities of those different departments. Those different priorities and guidelines posed another problem when they would be at odds with each other. Teams in Zalando would seek out guidance from SRE, not knowing which team to reach out to, or even that there were 2 separate teams. To understand how two SRE teams that were working together could offer inconsistent guidance, it’s important to remember that they belonged to different departments. The SRE DX team could focus on the problem space of the DX department and offer customized solutions for those teams. The SRE DF team had the entire company in scope, so whatever that team did, it had to be applicable on a different scale. The SRE Program was planned for the year of 2018, culminating with the end of Cyber Week. Following that plan, after Cyber Week was over the program ended and each team went back to work on projects relevant to their respective departments.
2019 - Combining forces as a single SRE team
In early 2019 both SRE teams were officially united into a single team in the DF department (the department of one of the original teams). With this merger, SRE now had a single voice in the company.
The experience with Distributed Tracing in the previous year was quite positive - Do you get the pun in the blog post’s name, now? 🤓. For one, it became a fundamental tool for incident response because it allowed for quicker insights, saving time from incidents. The coverage across Zalando’s services kept growing. The standardized data model and the development of Zalando specific Semantic Conventions, and an API to consume the tracing data allowed the SRE team to build additional value from it.
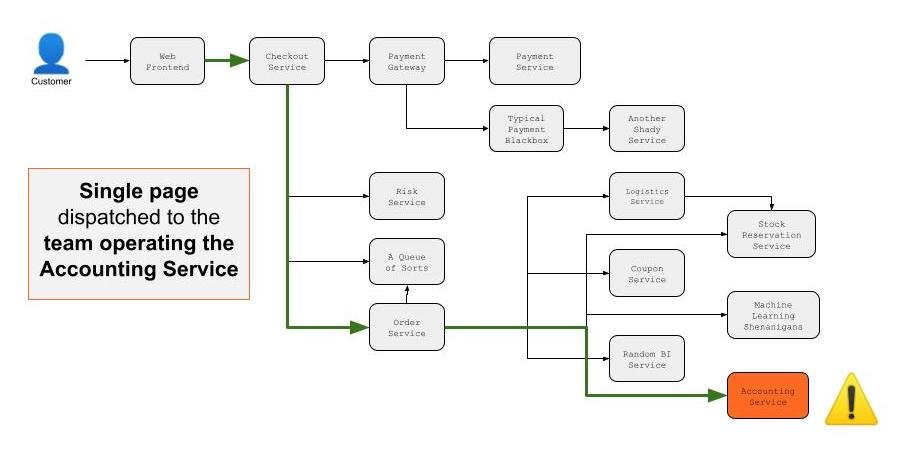
One of the tools we developed based on Distributed Tracing is an Alert Handler called Adaptive Paging (which we talked about in SRECon’19). This alert handler monitors the error rate of what we call Critical Business Operations1 (CBO) and when it is triggered it uses the tracing data to determine where the error comes from across the entire distributed system, and pages the team that is closest to the problem. This alert handler was also a game changer in our push for a different alerting strategy: Symptom Based Alerting. You can learn more about it in the slides of one of the talks we did on this topic.
A throughput calculator based on Tracing data is also developed that helped the Load Test efforts for Cyber Week preparations. By applying the expected throughput for a CBO, we could estimate the impact on all the components that are part of the same journey, usually through cascading remote procedure calls.

Finally, through our use of Distributed Tracing, and Adaptive Paging, we made a significant change in our SLO strategy. We moved away from service based SLOs, and started rolling out Operation based SLOs.
Through internal and external hiring we grew the team up to 7 SREs. But that team size notwithstanding, hiring was always a challenge. Then, and today. The combination of the required skill set for an SRE at Zalando and the different definitions of the SRE role across the industry, means many candidates do not meet the bar, or simply have a different skill set. Nevertheless, it was agreed that we would not compromise our hiring. While growing engineers and teaching the SRE mindset was something seen as positive (and definitely a way to scale the team further), with our reduced size we could not provide an effective mentorship. Any engineers we would hire needing that mentorship would not be set up for success.

Both 2018 and 2019 were successful years for SRE, but there are quite a few differences between the two. In 2018 we worked exclusively on topics that SRE did not own. We were a mix of a consulting team and a kitchen sink team. We either volunteered for some of the projects we worked on, or were asked to help due to capacity reasons or because the projects required a specific skill set. Our main challenge was how to decide what to work on. There was no mathematical formula to determine this. It was always a matter of balancing the following dimensions:
- Likelihood of success (Would we be in way over our head? Could we actually influence the outcome?)
- Company’s priorities
- Enablement (If we’re working with a team, will that team learn something from the engagement, or were we expected to do everything ourselves?)
In 2019 we still operated partially in the same kitchen sink/consulting mode, but the big difference is that in 2019 we started working on our own products, which also means we started taking some control of our roadmap.
Overall, 2019 was the year we started reaping the benefits of the achievements from the previous years. We had given a clear signal that a single (small) team of engineers dedicated to Reliability could bring significant benefits to an organization the size of Zalando. But, to an extent, we were also a victim of our success. Despite having our own backlog and a list of topics we wanted to work on, the team became increasingly more in demand from different parts of the organization. Our help was requested to improve Operational Excellence in departments, to assist in the roll out of major launches, to review Technical Design Documents, to help in PostMortem investigations, Cyber Week preparations, Production Readiness Reviews… As before, we had to pick our battles carefully. Accepting every challenge with our reduced capacity meant that we would likely do a poor job in all of them. And anything in our backlog that we had promised and wouldn’t deliver would also affect our reputation.
Things are starting to get interesting. After a few successful projects, SRE’s reputation in the company grew. We merged the two SRE teams into a single team, making sure that SRE could continue to grow unaffected by fragmentation. The SRE Guild kept on going, further spreading the SRE mindset. We grew the team, and even started to focus on our own backlog. But SRE is still a single, small, team in a very large organization. How far can we stretch this model? Well, that's what we're going to talk about in our last blog post on this series in one week's time.
EDIT 1: Don't stop now. The third and last part of our series is already available here.
Grossly summarizing it, Zalando is an e-commerce platform, so a Critical Business Operation is anything that affects our Business, like ‘Add To Cart’, ‘Place Order’ or ‘View Catalog’ ↩
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Backend Engineer!
